1. 介绍
自从有了requests以后,生活变得美好了很多,爬虫不用再用urllib这么难用的库。如果你还没有用过,赶紧去试一下。
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text
u'[{"repository":{"open_issues":0,"url":"https://github.com/...
对于大多数爬虫任务,基本步骤都是:
- 找到一个初始页面,获取页面的内容
- 获取页面中自己需要的部分信息
- 使用正则表达式获取页面内容中的links
- 对第3步中获取的link,重复前面3步
开发过爬虫的同学应该知道,使用正则表达式获取links是很繁琐的工作,此外,一个页面中并不是所有的link都是我们需要的,过滤起来也比较麻烦。
此外,要获取页面中的内容,更是麻烦,如果还要我们获取tag中的属性,那简直要了人命。
2. BeautifulSoup
BeautifulSoup就是用来解决上面的问题的,使用起来非常方便。典型的安装:
pip install BeautifulSoup
例如,对于上面的第二个问题,要找到页面中所有的links,如下所示:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
# soup = BeautifulSoup("<html>data</html>")
for link in soup.find_all('a'):
print(link.get('href'))
例如,我在编写知乎的爬虫的时候,对于每一个用户的”关注”页面,对于每一个关注对象,有如下的tag:
<div class="zm-profile-card zm-profile-section-item zg-clear no-hovercard">
.......
<a title="天雨白" data-hovercard="p$t$tian-yu-bai" class="zm-item-link-avatar" href="/people/tian-yu-bai">
<img src="https://pic4.zhimg.com/033204ff4f44d6f9463279ac08278e6b_m.jpg" class="zm-item-img-avatar">
</a>
.......
</div>
所以,解析单个关注的用户代码如下所示:
soup = BeautifulSoup(text)
# 通过属性找到这个div,对于每个用户,对对应于这样一个div
items = soup.find_all('div', class_="zm-profile-card zm-profile-section-item zg-clear no-hovercard")
for item in items:
# 获取这个div下的<a>标签的title属性
name = item.a.attrs['title']
# 获取这个div下的<a>标签下的<img>标签里面的src属性
avatar = item.a.img.attrs['src']
有了BeautifulSoup以后,爬虫操作就变得特别简单了。脏活累活别人都帮忙做好了。
3. 完成的知乎爬虫的例子
下面是我写的一个知乎爬虫的例子,还有很多优化的空间,先这样了吧。
- 首先,通过cookies进行认证,这样,就解决了知乎的登陆问题,尤其是输入验证码这个头疼的问题
- 通过requests获取用户的关系
- 通过BeautifulSoup解析用户的信息,并保存到Person对象中
- 如果用户已经crawl过了,则跳过
- 如果用户没有被crawl过,则加入到字典
- 如果爬取的信息,达到了最高限制,则保存爬取的信息然后退出
有了这些信息以后,我们可以干什么呢。这个就发挥自己的想象了,可以做的事情非常多,例如,你可以统计有多少用户的粉丝超过了1000,获取超过100个赞的用户占所有用户的比例,如果建立一张网络,你还可以看看是否自己到每一个人只需要6个link就够了。
当然,这里只是一个例子,你可以爬取用户的回答信息,然后抓取美女图片,这个就靠你自己发挥了。
完整的代码如下:
# -*- coding: utf-8 -*-
import json
import sys
import codecs
import requests
from bs4 import BeautifulSoup
class Person(object):
def __init__(self, name, avatar, url, bio, follwers, asks, answers):
self.__dict__.update({k: v for k, v in locals().items() if k != 'self'})
def to_dict(self):
return dict(name=self.name,
avatar=self.avatar,
url=self.url,
bio=self.bio,
follwers=self.follwers,
asks=self.asks,
answers=self.answers)
class ZhihuCrawler(object):
def __init__(self, cookies, user_list, handler=sys.stdout, max_size=30000):
super(ZhihuCrawler, self).__init__()
self.cookies = cookies
self.user_list = user_list
self.handler = handler
self.max_size = max_size
self.users = {}
def do_task(self):
while len(self.users) < self.max_size:
next_user_list = []
for user in self.user_list:
print(".......... crawl information of {0}".format(user))
try:
persons = self._post_a_request(user)
except Exception as err:
print("got an error: {0}".format(err))
else:
for person in persons:
if len(self.users) >= self.max_size:
return
elif self.users.has_key(person.url):
continue
else:
print ("........[{0}]: ".format(len(self.users)))
print json.dumps(person.to_dict(), ensure_ascii=False)
self.users[person.url] = person.to_dict()
""" url = "https://www.zhihu.com/people/tian-yu-bai" """
next_user_list.append(person.url.split('/')[-1])
self.user_list = next_user_list
def _post_a_request(self, user):
zhihu_url_format = """https://www.zhihu.com/people/{0}/followees"""
header_info = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1581.2 Safari/537.36',
'Host':'www.zhihu.com',
'Origin':'http://www.zhihu.com',
'Connection':'keep-alive',
'Referer':'http://www.zhihu.com/people/{0}/followers'.format(user),
'Content-Type':'application/x-www-form-urlencoded',
}
url = zhihu_url_format.format(user)
r = requests.get(url, headers=header_info, cookies=self.cookies, verify=False)
return self._parser_result(r.text)
def _parser_result(self, text):
"""
<div class="zm-profile-card zm-profile-section-item zg-clear no-hovercard">
<div class="zg-right"> <button data-follow="m:button" data-id="2a485980f91b756b2abbe92b7ca7f424" class="zg-btn zg-btn-unfollow zm-rich-follow-btn small nth-0">取消关注</button> </div>
<a title="天雨白" data-hovercard="p$t$tian-yu-bai" class="zm-item-link-avatar" href="/people/tian-yu-bai"> <img src="https://pic4.zhimg.com/033204ff4f44d6f9463279ac08278e6b_m.jpg" class="zm-item-img-avatar"> </a>
<div class="zm-list-content-medium">
<h2 class="zm-list-content-title"><a data-hovercard="p$t$tian-yu-bai" href="https://www.zhihu.com/people/tian-yu-bai" class="zg-link author-link" title="天雨白" >天雨白</a></h2>
<div class="ellipsis"> <span class="bio">习惯被叫男神了→_→女暴力狂、法律人</span> </div>
<div class="details zg-gray"> <a target="_blank" href="/people/tian-yu-bai/followers" class="zg-link-gray-normal">90207 关注者</a> / <a target="_blank" href="/people/tian-yu-bai/asks" class="zg-link-gray-normal">3 提问</a> / <a target="_blank" href="/people/tian-yu-bai/answers" class="zg-link-gray-normal">110 回答</a> / <a target="_blank" href="/people/tian-yu-bai" class="zg-link-gray-normal">130504 赞同</a> </div>
</div>
</div>
"""
persons = []
soup = BeautifulSoup(text)
items = soup.find_all('div', class_="zm-profile-card zm-profile-section-item zg-clear no-hovercard")
for item in items:
name = item.a.attrs['title']
avatar = item.a.img.attrs['src']
sub_item = item.find_all('div', class_="zm-list-content-medium")
url = sub_item[0].h2.a.attrs['href']
bio = sub_item[0].div.span.text
sub_item = item.find_all('a', class_="zg-link-gray-normal")
follwers, asks, answers = sub_item[0].text, sub_item[1].text, sub_item[2].text
persons.append(Person(name, avatar, url, bio, follwers, asks, answers))
return persons
def main():
cookies = dict(d_c0="AEDAlNQcDQqPTlqFM4upH3kPzGbY1jCcEY0=|1465458664",
_za="54d84ead-f3f1-47d4-b3a5-0d987888e8fd",
_zap="0fa63ba-9936-412d-941f-e3e1bee5f7e6",
_xsrf="e03ca7c4f2632180b98000129d61b8f",
__utmt="1",
__utmb="51854390.11.9.1471142691581",
__utmc="51854390")
user_list = ["mingxinglai.com"]
crawler = ZhihuCrawler(cookies, user_list)
crawler.do_task()
with codecs.open('data.txt', 'w', encoding='UTF-8') as f:
json.dump(crawler.users, f, indent=4, skipkeys=True, ensure_ascii=False)
if __name__ == '__main__':
main()
下面是分析的结果,统计知乎中户中,粉丝的个数。可以看到,如果一个人的粉丝超过50个,则超过了80%的知乎用户。

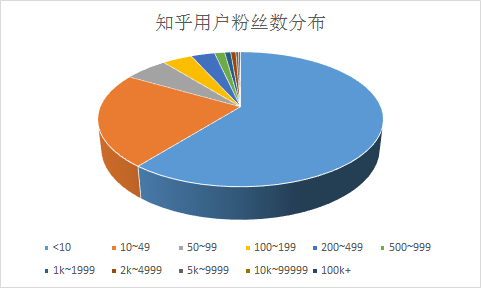
获取统计数据的代码如下:
#!/usr/bin/python
#-*- coding: UTF-8 -*-
import json
import codecs
with codecs.open('data.txt') as f:
data = json.load(f)
persons = data.values()
scale = [0, 10, 50, 100, 200, 500, 1000, 2000, 5000, 10000, 100000, 999999999999]
res = []
for i in range(len(scale)-1):
res.append( len(filter(lambda person: scale[i] <= int(person["follwers"].split()[0]) < scale[i+1], persons)))
print res
print [ round(float(item) * 100 / sum(res), 2) for item in res ]
完。